Bieg na Jawornik miejsce 26 open na 108 startujących. Start 11:00. Czas 1:52:07 waga 79,2 kg. Dystans 20,5 km 610 m up.
Przygotowanie – tydzień przed mocny BNP pod górkę, poniedziałek crossfit, wtorek średnie bieganie, czwartek lekkie krótkie bieganie w upale.
Fizycznie – na 14/15km po szybkim zbiegu i hopce 50m up złapał mnie skurcz w prawej łydce mięsień płaszczkowaty przyśrodkowa głowa. Musiałem na chwilę się zatrzymać i 2 sec rozciągnąć nogę. Wydaje mi się, że to przez supinację spowodowaną wciąż otwartą lewą stroną miednicy, w dalszym zbiegu starałem się bardziej pronować prawą stopę i problem nie już powrócił. Ciężko powiedzieć czy ta asekuracja wpłynęła na tempo biegu, pewnie nieznacznie tak, może ~1 min.
Kilka godzin po biegu czuję w lewej nodze ciągnące przyczepy brzuchatego.
Żywienie – dobrze, plan przedbiegowy zrealizowany, standardowo żel na 15 min przed startem a później po około 40 minut biegu na stromszym podejściu gdzie i tak przeszedłem w chód. Picie z uwagi, że organizator zapewniał kubki – łyknąłem po pół kubka na 2 punktach i raz pociągnąłem z flaska. Byłem dobrze nawodniony przed biegiem i nie czułem potrzeby pić więcej… ale, z uwagi na słońce i kosmiczne 26 stopni, może powinienem się bardziej zmusić.
Wniosek: jednak więcej pić
Jedzenie przed biegiem – dzień wcześniej po kolacji dodatkowa miska makaronu, pobudka o 7:20, standardowe 2,5 kromki kiełbasa i ser oraz miska makaronu. Na miejscu kilka daktyli, kawa, 40 min przed biegiem 2 łyżki makaronu. Zawsze obawiam się, że za mało jem i zwykle jem za dużo, tutaj chyba udało się uniknąć przeżarcia. Na początku biegu ciut chlupało w żołądku ale nie przeszkadzało.
Warunki – mega upał, o 11:00 na starcie 26 stopni i pełne słońce. Co prawda trasa w większości zacieniona ale było tez sporo odsłoniętych fragmentów i tam parzyło niemiłosiernie. Strzelam, że około 15-20% odsłoniętego było. Na około 3 km zdjąłem koszulkę co chwilowo dało ulgę.
Trasa – trasa mega prosta, w 100% szeroka dwutorówka, zero problemów z wyprzedzaniem. Ziemia, szuter, proste kamienie, może 2 km trochę zarośnięte i wyższa trawa ale nie przeszkadzało specjalnie.
Sprzęt – buty Brooks Catamount po raz kolejny (po maratonie 3xKopa) pokazały, że są do dupy. Na 9 km podbiegu zacząłem czuć lekkie boleści stóp jakby mimo sporej warstwy amortyzacji 19-25 mm mało tłumiły kamienie myślę, że przy dłuższym dystansie miałbym podobne bóle co na Kopie. Co dziwne czułem to tylko na podbiegu, na zbiegu nie. Poza tym dziwnie robią mi punkt podparcia na zewnętrznej krawędzi środka stopy, prawa obrywa bardziej. Jest to zdecydowanie do wyjaśnienia i chyba zakup innych butów. Co dziwne Brooks Catamount 1 spisywał się w obu elementach bez zarzutu, nawet teraz po kilometrażu prawie 1800 km. Reszta sprzętu gicior.
Przebieg – PacePro i RMT rozpisałem na 1:47:00 co wyceniało bieg na 501. Gdzieś do 5 km utrzymywałem zakładane tempo a nawet zrobiłem chwilowo -1 minutę. Pierwsze chwilowe przejście w chód na 5 km na dużym gradiencie, ale dosłownie kilka kroczków. Następnie kilka kilometrów bieg na 0 i 9,10,11 i pół 12 na gradiencie 10-14% zamuła i sporo chodu. Tempo 7:20 – 8:15 zaowocowało stratą ponad 6 min do docelowego czasu. Według garmina miałem 4:46 min czasu chodu.
Tego nie dało się już odrobić mimo iż PacePro na zbiegu nie zakładało kosmosu a jedynie około 4:40. Przed biegiem zakładałem, że jestem w stanie odrobić 4 minuty. Niestety na zbiegu były jeszcze 2 małe hopki oraz opisana wyżej przygoda z brzuchatym i odrobiłem tylko 1 minutę. Tempa 4:01 – 4:40 poza większą hopką gdzie wyszło 6:10. Na ostatnich 4,5 km tętno powyżej 170, miejscami 177 więc nie było z czego przyspieszyć.
Wniosek: gdy jest 80-100m przewyższeń na 1 km to nie daję radę w 100% biec.
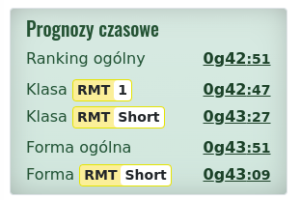
Ocena – 8/10. Nie znam jeszcze wyceny RMT wyścigu, RMT aktywności wyniosło rekordowe 624 ale wyścigowe raczej będzie poniżej 500. Na liście startowej byłem na 42 pozycji więc niby progres ale nie wiadomo ilu biegaczy z listy ostatecznie wystartowało. Warunki pogotowie bardzo trudne więc to podnosi ocenę, gdyby było 6 stopni to pewnie dałbym ciut mniej. Szacunki RMT niektóre pobite inne nie, forma ogólna prawie idealnie weszła. Jak jak mówię, wycena raczej nie uwzględniałą takiego upału. Zobaczymy na RTM official wyścigowy.

Mimo iż nie zacząłem wolno i wcale nie byłem ustawiony na tyle to w zasadzie tylko wyprzedzałem, na ostatnim km ktoś mnie wyprzedził ale nie mam pewności czy sam go wcześniej nie łyknąłęm. Cały bieg miałem w miarę równy GAP 4:32 – 5:36 to mnie bardzo cieszy – widać, że nawet trudniejsze kmy pod górkę nie poskutkowały większym zamuleniem. Fakt, że przewyższenia nie były za wielkie ale zawsze coś.
BNJ_Polmaraton_2024 – wyniki
aktywność w RTM
aktywność Strava