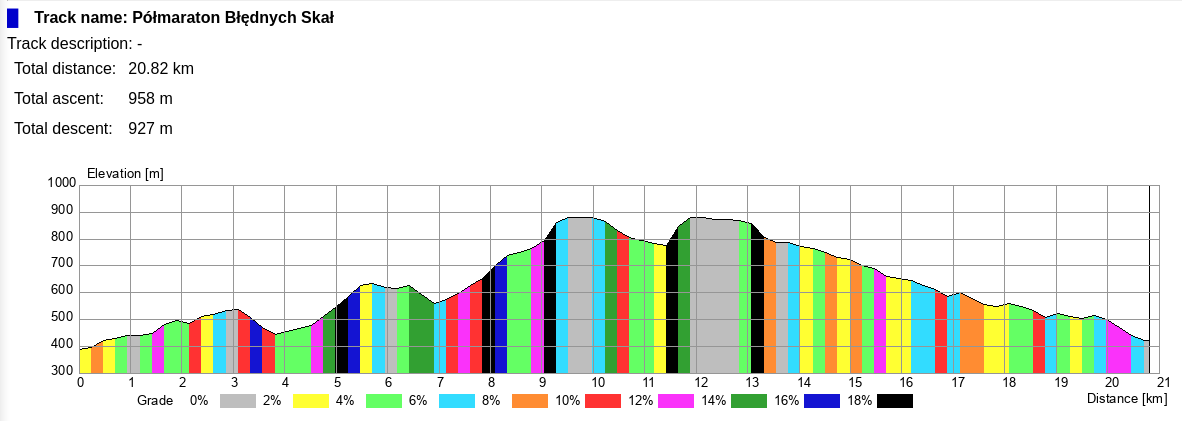
Zimowy Górski Półmaraton Ślężański miejsce 47 Open na 304 startujących. Start 10:00 sobota 11 stycznia 2025, czas: 2:14:02, waga: 75,7kg. Dystans 24km i 580m up.
Przygotowanie – pół listopada, cały grudzień i w styczniu aż do biegu robiłem wolne jednostki w tlenie, w grudniu wpadły 2 wypady na Ślężę. Spore natężenie treningowe ale na wolnych jednostkach, w ostatnim tygodniu tapering, we wtorek wpadło 4km @5:00 z pięknym tętnem 143 co zapowiadało bardzo dobry bieg.
Fizycznie – przystępowałem praktycznie w 100% zdrowy, czułem minimalne spięcie w prawym pośladku ale w treningach nigdy się nie odzywało, dobrze się wyrolowałem. Na biegu na szczytowym podejściu zaczęły mnie brać skurcze w łydkach (brzuchaty lub płaszczkowaty) – standardowo od wewnętrznej strony. Później łapały mnie jeszcze na zbiegu do Tąpadeł i na czarnym. Skórcze były na tyle delikatne, że nie musiałem zwalniać (jak np. na zbiegu w Jaworniku) ale nie chciałem zwiększać intensywności żeby coś złego się nie stało. Dziwne jest to, że na końcowych kilometrach już mnie nie łapały. Wydolnościowo bieg wybitny, pierwsze 5km na nosie, średnie tętno 158 bpm, chwilowy max 170. Na ostatnich kmach zamiast zdychać to miałem trzeźwy umysł, ogromna poprawa.
Wniosek, jak będę na jakimś treningu w górach wziąć marker i zaznaczyć tam gdzie mnie łapie żeby zidentyfikować mięsień.
Żywienie – idealnie. Wieczorem zagotowałem 300g makaronu, zjadłam z 70 a 230 rano + 1 kromka mojego chleba + warzywa + 3 plastry kiełbasy, przed sobótką pół batona. Czułem fajny luz w brzuszku. W domu kawka + 200mg kofeiny na 30 min przed startem. W biegu żywienie prawie idealne, żel 15 min przed biegiem, na 7 km i 14,5 km. Trochę mało piłem, na zbiegu po zakręcie na lewo byłem tak zasuszony że ciężko było przełykać, wcześniej chyba coś piłem raz ale za mało.
Wniosek: bardziej pilnować picie, wyznaczyć sobie sztywne ramy picia jak z żelami
Warunki – temperatura -1, odczuwalna niby -12 ale nie było tego czuć, oblodzenie tylko miejscami: końcówka ścieżki pod skałami, chopka i zbieg do Tąpadeł. Czarny w powrotnej drodze miejscami mocno błotnisty. Było wszystko: śnieg, woda, lód. Ogólnie warunki ciężkie ale lepsze niż w 2024.
Trasa – szeroka droga oprócz ścieżki pod skałami
Sprzęt – standardowy biegowy, na górze 2 warstwy, na głowie czapka z 2024 roku.
Przebieg – PacePro i RMT rozpisałem na 2:15 co wyceniło na 534 punktów RMT. W PacePro powpisywałem czasy z rozpiski RMT i dostosowałem segmenty mniej więcej tak żeby pasowało, dzięki temu miałem dużo lepszy ogląd na sytuację niż nierealne czasy z PacePro.
Pierwsze 7 km do ogniska miałem przewagę około minuty, później straciłem czas przez mini korek na końcówce ścieżki pod skałami (to dlatego zawsze tam mam dziwnie wolny międzyczas 1 km!) oraz jak zwykle trochę zamuliłem na podejściu, ale i tak był bardzo dobrze – co prawda nie utrzymałem zakładanego 8:17 ale było niewiele wolniej. Na szczycie miałem stratę do planu jakieś 35 sekundy. Całość odrobiłem na zbiegu i na żywieniowym miałem już zapas około 30 sekund. Na singlu wzdłuż asfaltu byłem mega silny aż się dziwiłem. Później też super się biegło, cały czas biegiem.
Średnie tempo 5,35 min/km i GAP często poniżej 5:00 cieszy.
Wniosek: trzeba by dość sporo szybciej pobiec początek, żeby nie być przyblokowanym na ścieżce pod skałami, nie wiem czy warto
Ocena – 10/10 Plan wykonany z nawiązką, w dodatku miałem jeszcze zapas wydolnościowy i spokojnie mógłbym podobnym tempem pobiec jeszcze kilka kilometrów. Można uważać, że powinienem z uwagi na to cisnąć bardziej ale byłem mega zadowolony z dyspozycji a z uwagi na łapiące skurcze nie chciałem przesadzić. Ostateczna ocena RMT ciut zaniżona bo tylko 530 mimo przybiegnięcia minutę szybciej ale to i tak mój mocno najlepszy wynik więc nie ma co marudzić.
Wniosek: na tej trasie jeszcze jest sporo minut do urwania!

Wyniki Datasport i PDF
aktywność w RMT
aktywność Strava





{kind=link}
{kind=link}